Groovy学习笔记之学霸分析仪
学霸分析仪
在Github上看源代码。
学霸分析仪概述
还是用上次笔记里面的jetty框架来写个学霸分析仪,功能如图:
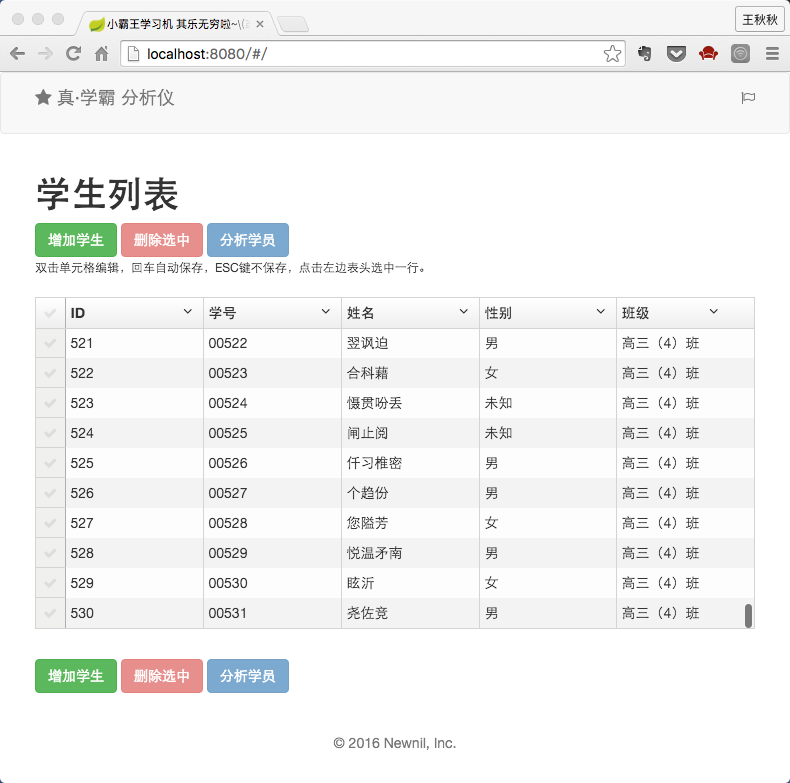
首页有张列表列出了数据库里的学生信息,包括学号、姓名、性别以及班级。点击左边表头可以选中学生,然后点击 分析学员 按钮,可以进入到分析页面。
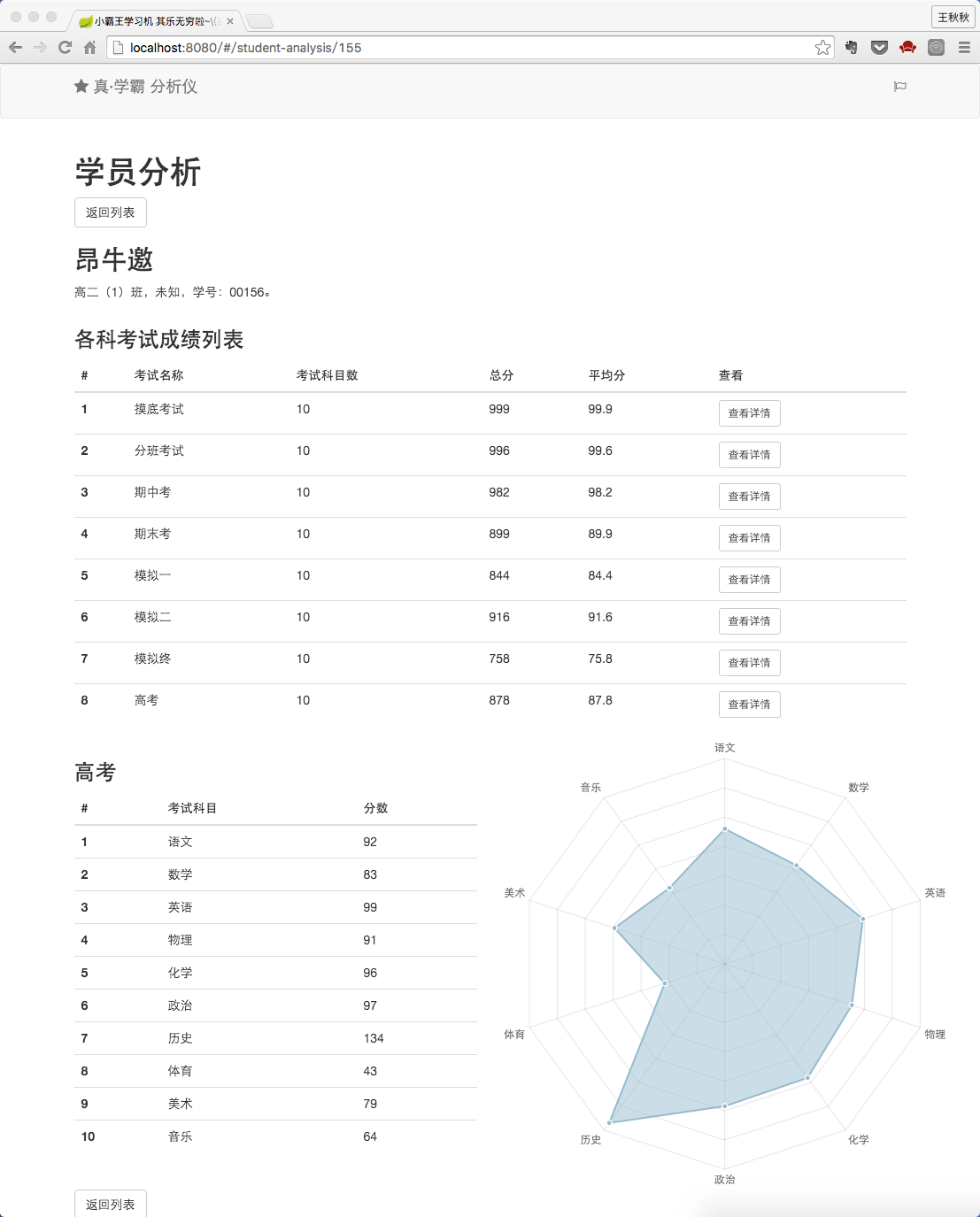
在学员分析页面,可以看到这个页面有学生的名字、班级、性别、学号以及各科考试的详细数据。并且点击考试右侧的 查看详情 按钮,会在下方显示出该同学在该场考试每门科目的具体分数,并配上一块雷达图显示各门分数的多少。
用到的技术
首先,
- 我们使用Groovy的Sql进行ddl和数据创建,然后数据库使用hsql。当然你可以很轻松地换成MySql、SQL Server以及Oracle啦。
- 后台有2个使用Groovy的jsonBuilder来暴露json格式数据的API,分别为
/api/exam.groovy和/api/student.groovy,分别为前台提供考试和学生信息供数据。 - 前台使用angularJs、bootstrap,雷达图使用chartJs实现。
本文重点会放在后台数据库上,不会讨论前台相关的问题。
DDL
首先,我们还是使用前篇文章提到的Jetty搭建服务器,所以有了app.groovy。然后,在里面手写SQL实现DDL。
像所有Java框架,执行SQL之前,首先需要有个dataSource。可以看到这里使用了hsqldb自带的JDBCDataSource,当然你也可以用譬如dbcp、c3p0或者光之cp之类的数据源池当做dataSource:
// ...
import org.hsqldb.jdbc.JDBCDataSource
// ...
def dataSource = new JDBCDataSource (
database: 'jdbc:hsqldb:file:magicMirrorDB',
user: 'sa',
password: ''
)
// ...然后把这个dataSource保存到Servlet的context里面去,给后面的操作使用。
context.with {
// other settings...
setAttribute('dataSource', dataSource)
// other settings...
}然后我们把这个dataSource包到Groovy.Sql里面去,然后使用Sql的方法来执行SQL。 譬如下面这段是创建Student表的DDL,可以看到这里我把整个DDL包到一个transaction的闭包里面去了,这样所有的ddl将属于同一个事务的操作。
// ...
Sql sql = new Sql(dataSource)
// ...
sql.withTransaction {
sql.execute '''
CREATE TABLE IF NOT EXISTS Student (
student_id INTEGER GENERATED BY DEFAULT AS IDENTITY,
student_no VARCHAR(50),
name VARCHAR(250),
gender VARCHAR(2),
class VARCHAR(50)
);
'''
// ... other ddls
}sql.execute后面跟的三个单引号是Groovy的字符串常量,可以在里面写很多从Java的角度看非法的字符串,譬如换行。这样写可以让代码整齐点。
CRUD
有了数据库Schema,就可以来操作数据了。譬如在/api/student.groovy中,我们可以通过POST方法来创建或更新一个学生数据;GET方法来获取学生信息;DELETE方法来删除数据。先看POST方法:
import groovy.json.JsonSlurper
// ...
def sql = new Sql(application.dataSource)
// ...
if ('POST' == request.method) {
def slurper = new JsonSlurper()
def data = slurper.parse(request.inputStream)
def studentId
sql.withTransaction {
if (data.id != null) {
// ...省略update
} else {
def keys = sql.executeInsert """
INSERT INTO Student (student_no, name, gender, class) VALUES ($data.studentNo, $data.name, $data.gender, ${data['class']})
"""
studentId = keys[0][0]
application.fillExams.call(studentId, sql)
}
}
json {
response 'OK'
id studentId
}
}
// ...首先我们从context中取出数据源dataSource并包装到Sql中。
然后如果request过来的方法是POST方法的话,使用groovy.json.JsonSlurper读取request的body,解析为data。然后判断data是否含有id,如果没有id的情况下,则使用sql来执行insert语句。
可以看到这里用了3连双引号来包含SQL(GString),这样groovy会去做字符串插值(string interpolation),这是其一,其二sql.executeInsert方法这边的字符串插值会被转换为PreparedStatement,不用担心SQL注入的问题(参考groovy.sql.Sql#Avoiding SQL injection)。
insert完成后,返回了自动生成的key,然后使用了之前提供的一个application.fillExams.call(studentId, sql)方法来为该id的学生填充随机生成的数据。最后使用jsonBuilder返回ok和学生id。
更新学生数据和之前一样,区别在于这次post过来的数据里面有id号:
// ...
if ('POST' == request.method) {
// ...
sql.withTransaction {
if (data.id != null) {
studentId = data.id
sql.executeUpdate """
UPDATE Student set student_no = $data.studentNo, name = $data.name, gender = $data.gender, class = ${data['class']}
WHERE student_id = $studentId
"""
} else {
// ...
}
}
json {
response 'OK'
id studentId
}
}
// ...然后我们来看看GET方法:
// ...
if ('GET' == request.method) {
if(params.studentId != null) {
def row = sql.firstRow("""
SELECT student_id, student_no, name, gender, class FROM Student WHERE student_id = ${params.studentId}
""")
json {
id row['student_id']
studentNo row['student_no']
name row.name
gender row.gender
'class' row['class']
}
} else {
def result = [];
sql.eachRow '''
SELECT student_id, student_no, name, gender, class FROM Student order by student_id
''', { row ->
result << [
id : row['student_id'],
studentNo: row['student_no'],
name : row.name,
gender : row.gender,
class : row['class']
]
}
json result
}
}
// ...在request.method为get的时候,判断是否有studentId传过来,如果有的话,使用sql.firstRow方法返回单行学生信息;如果没有的话,则使用sql.eachRow方法,并且传入一个闭包操作每一行的数据,这里把每行数据加入一个result的list中去。最后使用jsonBuilder输出结果。
然后我们看看DELETE方法:
if ('DELETE' == request.method) {
def delCount = 0
if (params.id) {
delCount = sql.executeUpdate """
DELETE FROM Student where student_id = $params.id
"""
}
json {
response 'OK'
count "$delCount"
}
}和想象中的一样,sql.executeUpdate返回影响到的行数。
Batch操作
除了上述简单的CRUD之外,还可以用Batch来批量操作SQL。我们来看看DataGenerator.groovy里面的fillExams方法是如何为学生填充随机分数的。
// ...
class DataGenerator {
// ...
def exams = ['摸底考试', '分班考试', '期中考', '期末考', '模拟一', '模拟二', '模拟终', '高考']
// ...
def fillExams = { studentId, sql ->
def sIds = []
if(studentId != null) {
sIds << studentId;
} else {
sql.eachRow('SELECT student_id FROM Student') { sIds << it.student_id }
}
def insertExamSql = 'INSERT INTO Exam(student_id, subject_id, name, score, sort)VALUES(?, ?, ?, ?, ?)'
exams.eachWithIndex { examName, index ->
sIds.each { student ->
sql.eachRow('SELECT subject_id FROM Subject') { subject ->
sql.withBatch insertExamSql, { ps ->
ps.addBatch(student, subject['subject_id'], examName, randScore(), index)
}
}
}
}
}
// ...
}实际上fillExams不是一个方法而是一个闭包,这样fillExams就可以作为方法对象来传递了。然后这个闭包接受2个参数:studentId和sql。其中studentId是学生的id号,sql则是sql操作对象。
fillExams首先判断有无studentId,如果无,则针对数据库中所有的学生进行操作,如果有则针对当前这个学生进行操作。然后insertExamSql定义了insert的语句,因为batch必须是PreparedStatement的,所以使用?来传递参数。针对exams列表中的中每一个考试,循环每一个学生id,使用sql.eachRow选出Subject表中每一个科目,并且针对每一个科目,使用sql.withBatch方法和ps.addBatch来增加batch。
嗯……其实我觉得吧,这里的sql.withBatch,应该放到最外面才对,应该像这样写:
// ...
def fillExams = { studentId, sql ->
// ...
def insertExamSql = ...
sql.withBatch insertExamSql, { ps ->
exams.eachWithIndex { examName, index ->
sIds.each { student ->
sql.eachRow('SELECT subject_id FROM Subject') { subject ->
ps.addBatch(student, subject['subject_id'], examName, randScore(), index)
}
}
}
}
}……好吧,反正能跑就行了,以后再改吧。
结论
好了本文到这里就大致介绍了Groovy的数据库操作的概况,但这只涵盖了学霸分析仪的一小部分,我不准备详细说自己看代码好了。看不懂也表问我了,这里是不负责任的讲解。
下一次讲如何把学霸分析仪改造成Spring框架的Groovy项目。
- 完 -

