spring-data-jpa源码阅读笔记:Repository方法名查询推导(Query Derivation From Method Names)的实现原理 2
Repository方法名查询推导(Query Derivation From Method Names)的实现原理 2
从魔法到现实
上次的文章我们讲到QueryExecutorMethodInterceptor这个类。
阅读这个类的源代码,我们发现,这个类实现了MethodInterceptor接口。也就是说它是一个方法调用的拦截器,
当一个Repository上的查询方法,譬如说findByEmailAndLastname方法被调用,Advice拦截器会在
方法真正的实现调用前,先执行这个MethodInterceptor的invoke方法。这样我们就有机会在真正方法实现
执行前执行其他的代码了。
然而对于QueryExecutorMethodInterceptor来说,最重要的代码并不在invoke方法中,而是在它的
构造器QueryExecutorMethodInterceptor(RepositoryInformation r, Object customImplementation, Object target)中。
最重要的一段代码是这段:
for (Method method : queryMethods) {
// 使用lookupStrategy,针对Repository接口上的方法查询Query
RepositoryQuery query = lookupStrategy.resolveQuery(method, repositoryInformation, factory, namedQueries);
invokeListeners(query);
queries.put(method, query);
}这段代码的主要工作是,通过lookupStrategy,针对Repository接口上所定义的方法来查询RepositoryQuery,
并在查询到的query上执行监听器(我们先忽略监听器),然后以method方法对象作为key,放入queries缓存中。
那么问题是lookupStrategy是哪里来的?往上翻我们发现
// 使用外部类RepositoryFactorySupport#getQueryLookupStrategy(..., ...)(两个参)
// 或者RepositoryFactorySupport#getQueryLookupStrategy(...)(一个参)
// 来获取lookupStrategy
QueryLookupStrategy lookupStrategy = getQueryLookupStrategy(queryLookupStrategyKey,
RepositoryFactorySupport.this.evaluationContextProvider);
lookupStrategy = lookupStrategy == null ? getQueryLookupStrategy(queryLookupStrategyKey) : lookupStrategy;
// 获取Repository接口上定义的方法
Iterable<Method> queryMethods = repositoryInformation.getQueryMethods();
// 如果没有找到lookupStrategy
if (lookupStrategy == null) {
// 并且Repository接口上定义了方法,则抛出状态错误,注意IllegalStateException是RuntimeException。
if (queryMethods.iterator().hasNext()) {
throw new IllegalStateException("You have defined query method in the repository but "
+ "you don't have any query lookup strategy defined. The "
+ "infrastructure apparently does not support query methods!");
}
// 如果Repository接口上没有定义方法,则中断初始化。
return;
}}
从这段代码我们可以看到,lookupStrategy是从外部类RepositoryFactorySupport上的getQueryLookupStrategy(...)方法来获取的。
阅读RepositoryFactorySupport的源代码,我们发现,无论是一个参数还是两个参数的getQueryLookupStrategy方法都是直接返回null,
所以是不可能通过这个两个方法来获取真正的实现的,那么lookupStrategy到底哪里来的呢。
答案在RepositoryFactorySupport的子类JpaRepositoryFactory中。在JpaRepositoryFactory中我们发现了
getQueryLookupStrategy(两个参数)的真正实现,它调用了JpaQueryLookupStrategy的静态create方法
public static QueryLookupStrategy create(EntityManager em, Key key, QueryExtractor extractor,
EvaluationContextProvider evaluationContextProvider) {
Assert.notNull(em, "EntityManager must not be null!");
Assert.notNull(extractor, "QueryExtractor must not be null!");
Assert.notNull(evaluationContextProvider, "EvaluationContextProvider must not be null!");
switch (key != null ? key : Key.CREATE_IF_NOT_FOUND) {
case CREATE:
return new CreateQueryLookupStrategy(em, extractor);
case USE_DECLARED_QUERY:
return new DeclaredQueryLookupStrategy(em, extractor, evaluationContextProvider);
case CREATE_IF_NOT_FOUND:
return new CreateIfNotFoundQueryLookupStrategy(em, extractor, new CreateQueryLookupStrategy(em, extractor),
new DeclaredQueryLookupStrategy(em, extractor, evaluationContextProvider));
default:
throw new IllegalArgumentException(String.format("Unsupported query lookup strategy %s!", key));
}
}可以看到,这个方法通过外部传入的key来返回不同实现的QueryLookupStrategy。如果外部key没有定义(为null)的话,
会返回CreateIfNotFoundQueryLookupStrategy的实现。通过名字可以知道这个实现其实只是一个代理,它会将真正的调用
根据情况转发到CreateQueryLookupStrategy以及DeclaredQueryLookupStrategy。
根据名称,我们就能大致猜测到这些实现类的作用以及区别了。CreateQueryLookupStrategy会根据方法名
创建查询;DeclaredQueryLookupStrategy则会尝试使用方法上的@Query注解来查找named query;
而CreateIfNotFoundQueryLookupStrategy则是会先尝试DeclaredQueryLookupStrategy,
如果没有找到则再去调用CreateQueryLookupStrategy。
另外说一下关于这个作为参数传入的key,如果你仔细看一下就会发现,这个key的来源其实是定义在RepositoryFactorySupport中的
域queryLookupStrategyKey,可以作为外部配置选项使用,并且默认并没有赋值,所以默认是null。因此该create方法其实默认会
返回CreateIfNotFoundQueryLookupStrategy的实现。
因为我们要找的重点是Repository方法名查询推导,所以我们先忽略DeclaredQueryLookupStrategy和
CreateIfNotFoundQueryLookupStrategy实现。让我们回到CreateQueryLookupStrategy实现中来。
在CreateQueryLookupStrategy实现中,我们可以看到它继承了AbstractQueryLookupStrategy抽象类,
并且覆盖了resolveQuery方法,返回了一个叫做PartTreeJpaQuery的RepositoryQuery实现,源码如下:
@Override
protected RepositoryQuery resolveQuery(JpaQueryMethod method, EntityManager em, NamedQueries namedQueries) {
try {
return new PartTreeJpaQuery(method, em, persistenceProvider);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException(
String.format("Could not create query metamodel for method %s!", method.toString()), e);
}
}其中PartTreeJpaQuery是重点。这个PartTreeJpaQuery就是前文所说的lookupStrategy返回的、被放入缓存的最终Query的实现。
所以需要重点阅读这个类的源代码。
PartTree
关于PartTreeJpaQuery,我们先来看一下它的继承结构。
PartTreeJpaQuery扩展自AbstractJpaQuery抽象类,并且AbstractJpaQuery实现了RepositoryQuery接口。
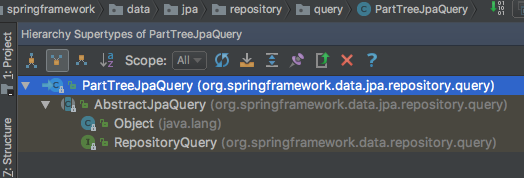
查询AbstractJpaQuery抽象类的子类我们看到,除PartTreeJpaQuery的实现外还有好多其他的实现,但这些实现并不是我们关注的重点,所以暂时忽略。
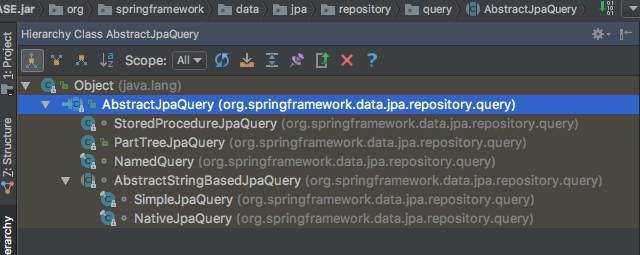
回到PartTreeJpaQuery实现,从该类的注释中我们获知,该类是基于PartTree的一个AbstractJpaQuery的实现。
AbstractJpaQuery implementation based on a PartTree.
打开PartTree类的源代码我们终于发现了奥秘所在之处:(代码注释)
Class to parse a String into a tree or PartTree.OrParts consisting of simple Part instances in turn. Takes a domain class as well to validate that each of the Parts are referring to a property of the domain class. The PartTree can then be used to build queries based on its API instead of parsing the method name for each query execution.
根据注释我们知道,该类通过将一个字符串(其实是Repository里面定义的方法名)分解成树状数据结构,或者说是分解成一系列
包含简单Part实例的OrParts来构建查询的。并且通过查询传入的domain class类型来验证每一个Part所对应的字段是否有效。
通过阅读代码,我们知道该类是通过正则表达式来分解类方法名的。
// 该段正则表达式在PartTree类中,主要作用是将一串方法名分解成主语(Subject对象)和谓语(Predicate对象)
/*
* We look for a pattern of: keyword followed by
*
* an upper-case letter that has a lower-case variant \p{Lu}
* OR
* any other letter NOT in the BASIC_LATIN Uni-code Block \\P{InBASIC_LATIN} (like Chinese, Korean, Japanese, etc.).
*
* @see http://www.regular-expressions.info/unicode.html
* @see http://docs.oracle.com/javase/7/docs/api/java/util/regex/Pattern.html#ubc
*/
private static final String KEYWORD_TEMPLATE = "(%s)(?=(\\p{Lu}|\\P{InBASIC_LATIN}))";
private static final String QUERY_PATTERN = "find|read|get|query|stream";
private static final String COUNT_PATTERN = "count";
private static final String DELETE_PATTERN = "delete|remove";
private static final Pattern PREFIX_TEMPLATE = Pattern.compile( //
"^(" + QUERY_PATTERN + "|" + COUNT_PATTERN + "|" + DELETE_PATTERN + ")((\\p{Lu}.*?))??By");
// ...省略...
/**
* Creates a new {@link PartTree} by parsing the given {@link String}.
*
* @param source the {@link String} to parse
* @param domainClass the domain class to check individual parts against to ensure they refer to a property of the
* class
*/
public PartTree(String source, Class<?> domainClass) {
Assert.notNull(source, "Source must not be null");
Assert.notNull(domainClass, "Domain class must not be null");
// 并且在其构造器中使用正则表达式分解方法名,将其分解为主、谓语两种对象。
Matcher matcher = PREFIX_TEMPLATE.matcher(source);
if (!matcher.find()) {
this.subject = new Subject(null);
this.predicate = new Predicate(source, domainClass);
} else {
this.subject = new Subject(matcher.group(0));
this.predicate = new Predicate(source.substring(matcher.group().length()), domainClass);
}
}
主语对象(Subject)和谓语对象(Predicate)分别表示了方法名中的不同部分,譬如给定方法名
findDistinctUserByNameOrderByAge
通过上述正则表达式解析,则分成主语部分DistinctUserBy和谓语部分NameOrderByAge。
在Subject类(主语类)中,还将继续通过正则表达式进行分解,提取法语中distinct、count、delete和maxResults几种属性。
/**
* Represents the subject part of the query. E.g. {@code findDistinctUserByNameOrderByAge} would have the subject
* {@code DistinctUser}.
*
* @author Phil Webb
* @author Oliver Gierke
* @author Christoph Strobl
* @author Thomas Darimont
*/
private static class Subject {
private static final String DISTINCT = "Distinct";
private static final Pattern COUNT_BY_TEMPLATE = Pattern.compile("^count(\\p{Lu}.*?)??By");
private static final Pattern DELETE_BY_TEMPLATE = Pattern.compile("^(" + DELETE_PATTERN + ")(\\p{Lu}.*?)??By");
private static final String LIMITING_QUERY_PATTERN = "(First|Top)(\\d*)?";
private static final Pattern LIMITED_QUERY_TEMPLATE = Pattern.compile("^(" + QUERY_PATTERN + ")(" + DISTINCT + ")?"
+ LIMITING_QUERY_PATTERN + "(\\p{Lu}.*?)??By");
// ...省略...
public Subject(String subject) {
// 继续通过正则表达式分析下列几种属性,为之后构建查询做准备。
this.distinct = subject == null ? false : subject.contains(DISTINCT);
this.count = matches(subject, COUNT_BY_TEMPLATE);
this.delete = matches(subject, DELETE_BY_TEMPLATE);
this.maxResults = returnMaxResultsIfFirstKSubjectOrNull(subject);
}在Predicate类(谓语类)中,如果方法名中有AllIgnoreCase或者AllIgnoringCase,则首先从改方法名中剥除该字段,
并且标示alwaysIgnoreCase无视大小写flag为true。然后,如果方法名中有OrderBy则首先对该方法名使用OrderBy进行分割,
再然后针对分割后不包含OrderBy的部分,通过关键字Or进行分割。譬如给定宾语
NameAndAgeOrGenderAndLocationOrderByDistanceAllIgnoringCase
通过分割后变成(AllIgnoringCase被剥离)
(NameAndAge)Or(GenderAndLocation)OrderBy(Distance)
其中(NameAndAge)和(GenderAndLocation)被分别包装成OrPart对象作为节点;(Distance)则被包装成OrderBySource对象另行对待。另外,其中OrderBySource对象只允许有1个。
在OrPart中我们可以看到,它再次使用正则表达式,使用And关键字对已分割的OrPart进行分割,最后包装成Part对象作为子节点。
这样来说的话,其实在Predicate类中,实际上是已经构建了一颗语法树。还是拿之前的例子来说的话,就是
Predicate根节点OrPart子节点(NameAndAge和GenderAndLocation)Part叶节点(Name和Age、Gender和Location,分别属于不同的上一级子节点,可以看到每一个叶节点均为实体类的属性)
在Part类中我们看到,除了针对该叶节点是否无视大小写的处理外,还分别解析了改叶节点的类型(由内部枚举类型Type定义)和
针对实例类型的属性路径(使用PropertyPath#from方法构建的PropertyPath类型属性)。
其中叶节点类型Type分别定义了该字段类型对应的关键字(Between、Exists、Like、NotNull等)和参数个数
(譬如Between需要2个参数才能确定,而NotNull则不需要参数)信息。
而PropertyPath则定义了访问某一属性所需要的属性路径,譬如FindByLocation_Nation_Address可能对应访问一个实体类的
entity.location.nation.address的属性所需要的路径。
到此为止,针对Repository中定义的方法名称创建查询的解析就已经做完了。完成后的解析会以PartTreeJpaQuery对象的方式放置
在内存中(RepositoryFactorySupport#QueryExecutorMethodInterceptor.queries,注意是个ConcurrentHashMap)。
待到相应的查询执行时,就会从queries中取出并执行相应的查询。
需要特别注意的是,这些放置在内存中的PartTreeJpaQuery会在初始化阶段(构造器中)去创建相应的JPA CriteriaQuery,
所以如果我们在Repository接口中不小心定义了一个错误的方法名,在Spring容器启动时就应该能看到报错了。
到此为止,Repository方法名查询推导(Query Derivation From Method Names)的实现原理就算理解完成了,你看懂了么?
- 完 -

